*Udemy의 "The Complete Web Developer in 2019 : Zero To Mastery" 강의에서 학습한 내용을 정리한 포스팅입니다.
*https://soldonii.github.io에서 2019년 8월 14일(수)에 작성한 글을 티스토리로 옮겨온 포스팅입니다.
*자바스크립트를 배우는 단계라 오류가 있을 수 있습니다. 틀린 내용은 댓글로 말씀해주시면 수정하겠습니다. 감사합니다. :)
1. Introduction to Database
개발자가 특정 웹사이트, 제품을 만든다면 데이터베이스를 구축하는 것은 필수이다. 그렇다면 데이터베이스란 무엇일까? 데이터베이스는 말 그대로 '데이터들의 모음'이다. 이 데이터베이스의 구축, 조직화, 관리 등을 쉽게할 수 있도록 도와주는 시스템을 DBMS(Database Management System)이라고 한다. 서버와 데이터베이스 간의 통신(데이터 저장, 업데이트, 수정, 삭제 등) 작업을 수행해주며, 아래 사진 속 Node Server와 데이터베이스 두개의 축을 합친 것이 바로 DBMS이다.
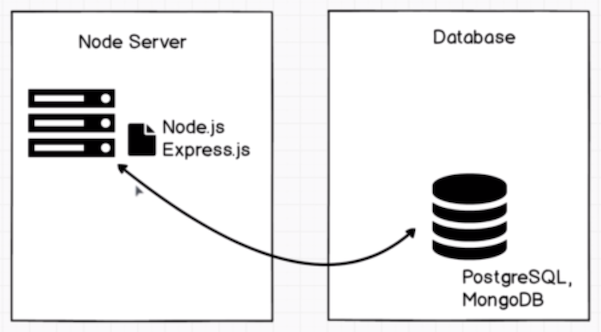
# DBMS의 2가지 종류
DBMS의 종류는 크게 2가지이다. ① 관계형 데이터베이스(Relational Database, PostgreSQL이 대표적) ② 비관계형 데이터베이스(Non-Relational Database, MongoDB가 대표적)이다.

PostgreSQL 뿐 아니라, Oracle, MySQL 같은 제품들 또한 대표적인 관계형 데이터베이스 기반 제품이다. 관계형 데이터베이스에 속하는 제품들은 모두 유사한 표준을 따르기 때문에 한 제품의 사용법을 알면 나머지 제품을 사용하는 것이 크게 어렵지는 않다.
관계형 데이터베이스는 n개의 데이터 테이블, 그리고 각 테이블 간의 정보를 유기적으로 연결짓는 schema 개념이 핵심이다. 위 사진에서 화살표로 연결된 것이 schema인데, schema는 PRIMARY KEY와 FOREIGN KEY를 활용해서 각 테이블 간 정보를 연결해서 주고받게 된다.(위 사진의 경우, users 테이블 속 username이 PRIMARY KEY이며, tweets 테이블 속 username은 FOREIGN KEY에 해당된다.)
테이블은 위 사진처럼 행과 열로 구성이 되어 있다.
- 열(column) : 각각의 열은 고유한 이름을 가지고 있고, 자신만의 데이터 타입을 가지고 있다.
- 행(row) : 행은 열의 속성을 모두 가지고 있는 데이터의 묶음이다.
PRIMARY KEY의 경우 한 테이블 내에 존재하는 여러 개의 열(column) 중에서 행(row)에 저장된 값을 고유하게 식별할 수 있는 식별자로, 사용자가 지정할 수 있다. 예를 들면, id, email, name, password, region 등 user의 다양한 정보들 중 고유하게 사용되는 것은 id이므로 id를 PRIMARY KEY로 지정할 수 있다.
FOREIGN KEY는 B라는 테이블에서 A라는 테이블의 행(row)에 접근하게 위해 사용하는 식별자 키이다. 예를 들면, tweets 테이블에서 username FOREIGN KEY를 이용해서 users 테이블에 접근할 수 있다. username이 "Andy"일 경우, tweets 테이블에서는 "Andy"의 full_name을 알 수 없지만, FOREIGN KEY(username)을 사용해서 users 테이블에 접근하고, users 테이블에서 "Andy"를 username 열의 값으로 가진 행(row)를 찾아내서 full_name의 값을 가져올 수 있는 것이다.
대부분의 관계형 데이터베이스는 SQL 언어를 사용한다. HTTP(Hyper Text Transfer Protocol)를 통해 클라이언트 사이드(front-end)와 서버 사이드(back-end) 간에 요청(request)과 응답(response)를 주고 받은 것처럼, 서버와 데이터베이스가 서로 의사소통하며 데이터의 삽입/추가/수정/제거/추출 등을 할 때 사용되는 언어이다.

MongoDB 같은 비관계형 데이터베이스 프로그램은 관계형 데이터베이스와 달리, schema를 먼저 설정하지 않고도 데이터베이스를 만들 수 있다. 관계형 데이터베이스의 경우, 앱이 사용자에게 어떻게 보일지에 따라서 데이터베이스 구축 이전에 설계를 먼저 해놓아야 한다. 만약 어떠한 데이터가 요구될지 명확하지 않고, 구조화되지 못한 엄청난 양의 데이터가 있을 경우는 관계형 데이터베이스를 이용해서 사전에 구조를 구축하는 것이 어려울 수도 있다.
반면 비관계형 데이터베이스는 폴더와 같다고 생각할 수 있고, 비관계형 데이터베이스 제품 중 하나인 MongoDB는 document oriented한 특성, 즉 모든 정보를 document 형식으로 저장하는 특성을 가지고 있다. 예를 들어보자.
관계형 데이터베이스의 경우 users.txt, tweet.txt, following.txt, image.txt 등의 파일로 데이터가 구조화 되어있고, 사용자의 팔로잉 수를 알려면 following.txt 파일에서 사용자의 이름을 알 수 있는 FOREIGN KEY를 통해서 users.txt 파일에서 해당 사용자의 이름을 불러와야 한다.
비관계형 데이터베이스의 경우, user1.txt, user2.txt, user3.txt와 같은 방식으로 데이터가 저장되어 있다. 그리고 각 파일 안에는 해당 유저에 대한 모든 정보를 저장해 놓는 형식이므로 해당 유저의 데이터에만 접근하면 모든 정보를 얻을 수 있다.
관계형이 비관계형보다 또는 반대의 경우가 무조건 더 낫다고 할 수는 없다. Andrei가 항상 강조하지만, 프로그래밍 패러다임에 절대적인 것은 없다. "무조건 이걸 써야 돼!"라는 태도보다는, "A는 B 대비 장단점이 뭐지? 그럼 이 상황에서는 어떤 솔루션이 더 효율적일까?" 와 같은 방식으로 접근해야 하며, 그렇기 때문에 어떤 것을 사용할 때는 그 방식의 장단점과 그 방식을 취한 이유를 알고 사용해야 하는 것이다.
마찬가지로 데이터베이스는 내가 만들고자 하는 제품의 상황에 따라서 어떤 데이터베이스가 더 효율적일지가 다르다. 예를 들어 이용자의 프로필 정보를 가져와야 한다면, MongoDB 같은 비관계형 데이터베이스를 사용하는게 편할 것이다. 하지만 만약 트위터 이용자들의 평균 tweet 사이즈를 알아야 할 경우에는 관계형 데이터베이스가 더 효율적일 것이다.

마지막으로 비관계형 데이터베이스 기반 프로그램은 SQL 언어를 사용하지 않는다. 목적은 같지만 사용하는 언어는 다르다.(Mongo DB의 경우 MongoDB Query Language라는 고유의 언어를 사용한다.)
2. SQL 명령어
- brew install postgresql : 컴퓨터에 PostgreSQL 설치
- brew services start postgresql : PostgreSQL 실행
참고로 PSequel은 PostgreSQL을 더 쉽게 사용할 수 있도록 도와주는 GUI로 설치하면 좋다.
# PostgreSQL 관련 명령어
- psql {database file name}; : 입력한 이름을 가진 데이터베이스 파일이 생성된다.(ex. psql test : test란 이름의 데이터베이스 생성)
- CREATE TABLE table_name (column1_name datatype, column2_name datatype, column3_name datatype...); : table_name에 해당되는 테이블을 생성하고, 각 열의 이름과 데이터 타입을 지정해준다.
- ☞ PostgreSQL 데이터타입
- \d : 현제 테이블의 구조를 보여준다.
- \q : 현제 테이블에서 나와서 터미널로 돌아간다.
- INSERT INTO table_name (column_1, column_2, column_3) VALUES (value_1, value_2, value_3); : 테이블에 값을 추가한다. 참고로 명령어는 대문자로 쓰는 것이 표준이지만, 소문자도 관계는 없다.
- SELECT col1_name, col2_name, col3_name FROM table_name; : \d 명령어로는 테이블의 구조만 알 수 있다. 테이블의 구조 뿐 아니라 값까지 알고 싶을 땐 SELECT 명령어로 보길 원하는 열을 선택하면 된다.
- SELECT * FROM users; : *은 모든 것을 선택하겠다는 의미이다.
- ALTER TABLE table_name ADD column datatype; : 테이블에 열을 추가한다.
- UPDATE table_name SET some_column = some_value, WHERE some_column = some_value; : 특정 열의 데이터 값을 추가 및 수정할 때 사용한다. 예를 들어, Andrei의 score 값을 50으로 주고 싶다면,, ⇒ UPDATE users SET score = 50 WHERE name = "Andrei"; 라고 입력하면 된다. 만약 동일한 값을 여러 열에 추가하고 싶다면,
- UPDATE table_name SET some_column = some_value, WHERE some_column = some_value OR some_column = some_value; : 예를 들어, John과 Sally의 score를 100점으로 값을 주고 싶다면 UPDATE users SET score = 100 WHERE name = "John" OR name = "Sally"; 이다.
A로 시작하는 특정 값들을 모두 선택하고 싶다면,
- SELECT * FROM users WHERE name LIKE 'A%'; : LIKE 키워드를 통해 조건을 달 수 있다. 'A%'는 뒤에 어떤 값이 와도 상관없이 A로 시작하는 값을 모두 선택하겠다는 의미이다.(참고로 대소문자를 구문하기 때문에 'a%'라고 할 경우 소문자 a로 시작하는 값만을 선택한다. 따라서 데이터베이스에 데이터를 저장할 때에는 통일된 규칙이 필요하다.(대소문자 구분 없이 무조건 소문자로만 데이터를 저장한다든지..))
- SELECT * FROM users ORDER BY score DESC; : 내림차순으로 정렬
- SELECT * FROM users ORDER BY score ASC; : 오름차순으로 정렬
- SELECT AVG(score) FROM users; : AVG가 함수명이다. 파라미터로는 평균을 구하고자 하는 열의 이름을 넣는다.
- SELECT SUM(score) FROM users; : 합계를 구하는 함수
- SELECT COUNT(score) FROM users; : 개수를 세는 함수
3. Joining Tables
앞서 말했듯, 관계형 데이터베이스는 한 데이터베이스 내 여러 개의 테이블 간 연결을 통해 다른 테이블의 값을 가져올 수 있었다. 어떻게 테이블 간에 연결을 부여할지 살펴보자.
CREATE TABLE login (
ID serial NOT NULL PRIMARY KEY,
secret VARCHAR (100) NOT NULL,
name text UNIQURE NOT NULL
);
위 코드는 login이라는 테이블을 생성하고, 그 안에 열의 이름과 데이터 타입 등을 지정한 것이다. 간단히만 살펴보면..
- serial : 행이 추가될 때마다 값이 하나씩 auto-increment 되도록 한다.
- NOT NULL : 이 열은 반드시 값이 채워져야 함을 의미한다.
- PRIMARY KEY : 테이블 내의 여러 열 중 unique한 값을 가지는 열을 선택해서 PRIMARY KEY로 지정한다. 지정한 PRIMARY KEY를 통해서 다른 테이블에서 login 테이블에 접근하여 정보를 찾을 수 있다.
- VARCHAR(100) : 최대 100개의 문자 수까지 포함할 수 있는 string data type이다.
- UNIQUE : name 열의 값들이 서로 중복되지 않도록 한다.
이 코드를 통해서 login 테이블이 생성되었고, 기존에 users 테이블에서 name 열에 Andrei, Sally, John 등의 값을 부여한 상태이기 때문에 이제 users 테이블의 PRIMARY KEY인 name 열을 login 테이블의 name 열이 FOREIGN KEY가 되어 users 테이블의 name 열을 레퍼런싱 하여 users 테이블의 다른 값들을 가져올 수 있다.
하나의 데이터베이스, 하나의 테이블에 모든 정보를 모으지 않고 PRIMARY KEY, FOREIGN KEY를 통해 값을 referencing 하는 이유는 마치 HTML, CSS, Javascript 파일을 따로따로 관리하는 separtion of concerns의 개념과 유사하다. 각 테이블이 필요한 최소한의 정보들만 가지고 있어야 데이터베이스의 속도와 효율성이 올라간다.
현재까지의 진행상황에서, 데이터베이스 내의 테이블을 확인하기 위해 \d 명령어를 입력하면 내가 생성하지 않은 것이 조회된다.
test=# \d
List of relations
Schema | Name | Type | Owner
--------+--------------+----------+---------
public | login | table | SOLDONI
public | login_id_seq | sequence | SOLDONI
public | users | table | SOLDONI
(3 rows)
login_id_seq는 내가 생성한 것이 아닌데 얘의 정체는 무엇일까?
특정 테이블에서 PRIMARY KEY를 생성하면, PostgreSQL은 PRIMARY KEY를 담고 있는 또 다른 파일(login_id_seq)을 생성한다. 업무적으로 이 파일에 접근할 일은 거의 없겠으나, PostgreSQL이 내부적으로 이 파일을 생성함으로써 각기 다른 테이블들이 서로의 정보를 가져오는 속도가 무척이나 빨라진다.
이제 본격적으로 PRIMARY KEY와 FOREIGN KEY를 이용하여 다른 테이블의 정보를 가져와보자. 현재 users 테이블에서는 name 열이 PRIMARY KEY로 설정되어 있기 때문에 이를 기준으로 값을 가져와야 한다.
SELECT * FROM users JOIN login ON users.name = login.name;
name | age | birthday | score | id | secret | name
--------+-----+------------+-------+----+--------+--------
Andrei | 31 | 1930-01-25 | 50 | 1 | abc | Andrei
Sally | 41 | 1930-01-04 | 100 | 2 | xyz | Sally
John | 45 | 1935-04-04 | 100 | 3 | lol | John
(3 rows)
- users 테이블에 login 테이블을 JOIN하는데, 이 때 users 테이블의 name 열의 값과 login 테이블의 name 열의 값이 동일한 행의 정보를 가져와 붙이라는 의미이다.
- JOIN 키워드를 통해서 users 테이블에 있는 age, birthday, score 뿐 아니라 login 테이블의 열인 id, secret 값 또한 가져왔다.
4. SQL: Delete From + Drop Table
테이블에서 특정 값을 지우고자 할 경우에는?
DELETE FROM users WHERE name='Sally';
test=# SELECT * FROM users;
name | age | birthday | score
--------+-----+------------+-------
Andrei | 31 | 1930-01-25 | 50
John | 45 | 1935-04-04 | 100
Amy | 15 | 1935-04-04 | 88
테이블 자체를 지우고 싶다면?
DROP TABLE login;
DROP TABLE users;
/* test=# \d
Did not find any relations. */
'Javascript 공부 > Zero To Mastery(-)' 카테고리의 다른 글
| (20) Node.js와 Express.js 2 (0) | 2019.08.27 |
|---|---|
| (19) Node.js와 Express.js 1 (0) | 2019.08.27 |
| (18) 백엔드 기본 (0) | 2019.08.27 |
| (17) HTTP/JSON/AJAX + 비동기적 자바스크립트 2 (0) | 2019.08.27 |
| (16) HTTP/JSON/AJAX + 비동기적 자바스크립트 1 (0) | 2019.08.27 |




댓글